~의(초보자 웹 크롤러는 랜덤으로 따라옴) 파이참 시작, 라이브러리 설치, html 로딩, 웹 데이터 로딩, 요청, 인쇄, 텍스트
#03 요청 패키지로 html 불러오기
웹 크롤링의 첫 번째 단계는 웹 페이지를 구성하는 html 문서를 내 컴퓨터에 로드예. 웹 브라우저에 표시되는 모든 정보는 html로 구조화되어 있으며 웹 크롤링은 이 html 문서를 검색하여 필요한 정보를 추출합니다. 모든 정보가 html로 고정된 정적 페이지와 페이지의 요청에 따라 서버에서 실시간으로 정보를 주고받는 동적 페이지가 있습니다.
01. 설치 패키지
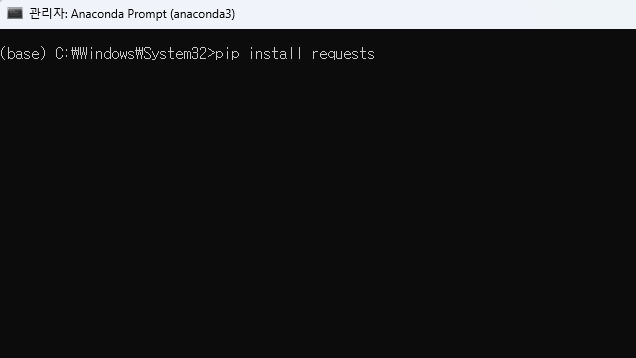
내 컴퓨터에 html을 로드하려면’필요하다‘ 패키지를 사용해야 합니다. 패키지(또는 라이브러리)는 자유롭게 다운로드하여 사용할 수 있는 특정 기능에 대한 기능 코드 집합입니다.패키지 다운로드 “아나콘다 프롬프트(아나콘다 3)” 실행데스크톱 작업 표시줄에서 검색을 통해 “Anaconda Prompt(anaconda 3)”를 쉽게 찾을 수 있도록 해야 합니다.. “아나콘다 프롬프트(아나콘다 3)” 실행 후, pip3 설치 요청 라고 입력하고 엔터를 누르면 설치가 완료됩니다.
pip install requests
02. HTML 불러오기
패키지를 설치한 후 Jupyter 노트북의 셀에서 수입 요청요청 모듈을 활성화합니다. HTML을 로드하는 코드 requests.get()~처럼 괄호호에 “url” 주소를 입력하십시오.아래에그렇다면 그렇습니다. 테스트로 접힌 html 위에 Chrome을 로드해 보겠습니다.
import requests #request 모듈을 활성화
response = requests.get("https://www.google.com/")
print(response)
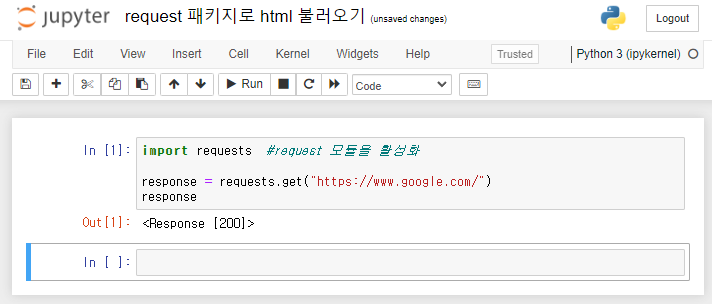
html을 출력하는 코드는 response로 정의하고 print()를 사용하여 결과를 확인합니다.셀을 실행하면 <响应 (200)>나는 그것이 무엇인지 모르지만 Google 주소에서 무언가가 호출되었음을 알 수 있습니다.
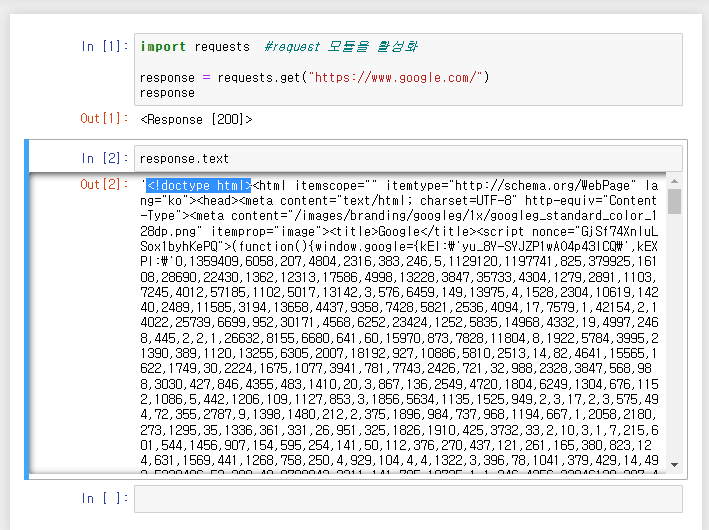
이번에는 응답에 .text 메서드를 추가하여 다시 실행해 보겠습니다.결과 창에서 ~에 의해 처음에 코드이 출력을 확인할 수 있습니다. 요청을 통해 html을 url로 요청하고, 얻은 html을 크롬 홈페이지의 모든 정보를 포함한 텍스트 형태로 출력합니다.
response.text
*package(library): 특정 기능을 포함하는 기능 코드 패키지
*Function: 함수를 실행하기 위한 명령어 코드
* 메소드: 속성 및 동작을 지정하는 코드
*변수: 임의 할당, 약어 정의, 사용하기 쉬움
ex) 응답으로 print(request.get(“~url~”)) 정의
다음으로 로드된 html에서 실제 텍스트 정보를 추출해 보겠습니다.
▼ 다음편에 계속 ▼
(Python: Web crawling) #03 html에서 선택자 경로 찾기
(초보 웹 크롤러는 혼란스럽게 따라옴) html, 태그, css 선택자, xpath, 경로 검색, 작업 지옥 탈출에 대한 데이터 검색 이해 (feat. 비즈니스 자동화) #03 html HTML 구문에서 선택자 경로 찾기
charimlab.